
Web Crawler
Web Crawler是德勤TAC自主开发的企业数据统一采集系统,完整地实现了生产者消费者模型。通过定时触发机制抓取公开的、权威的企业关键信息并实时记录分析汇总,形成行业报告。
适用于: 企业分析
Web Crawler是德勤TAC自主开发的企业数据统一采集系统,完整地实现了生产者消费者模型。通过定时触发机制抓取公开的、权威的企业关键信息并实时记录分析汇总,形成行业报告。
适用于: 企业分析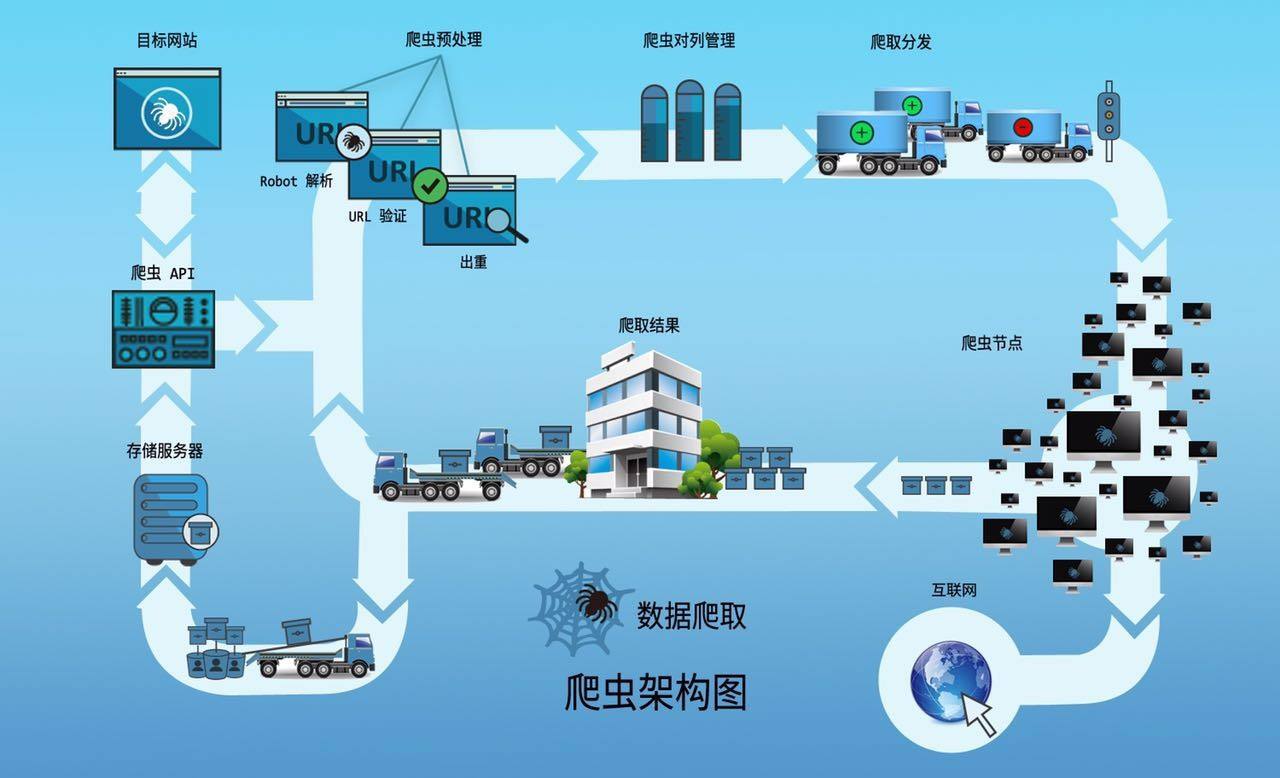

需要验证码;网站按行政区分别搭建系统,流程基本一致,需要可以方便调整的系统。
实现了一个省份的数据获取。
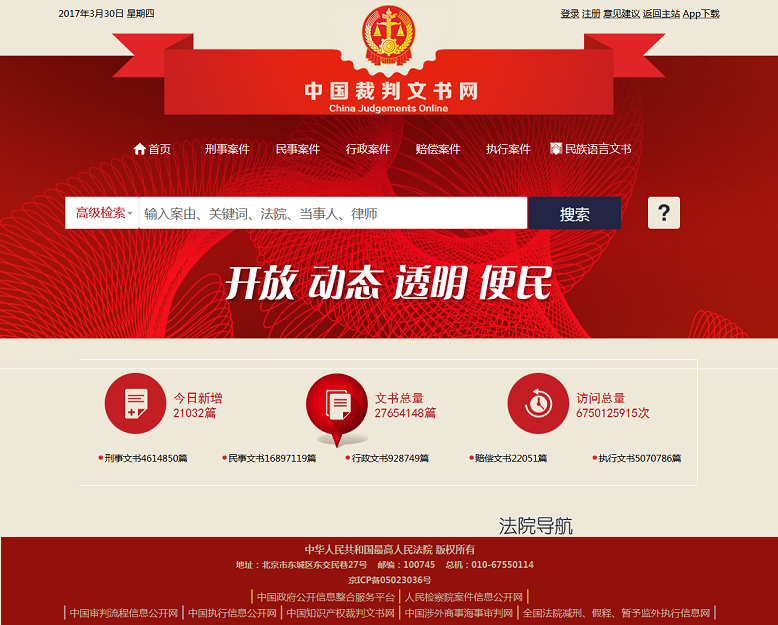
最终抓取成功!
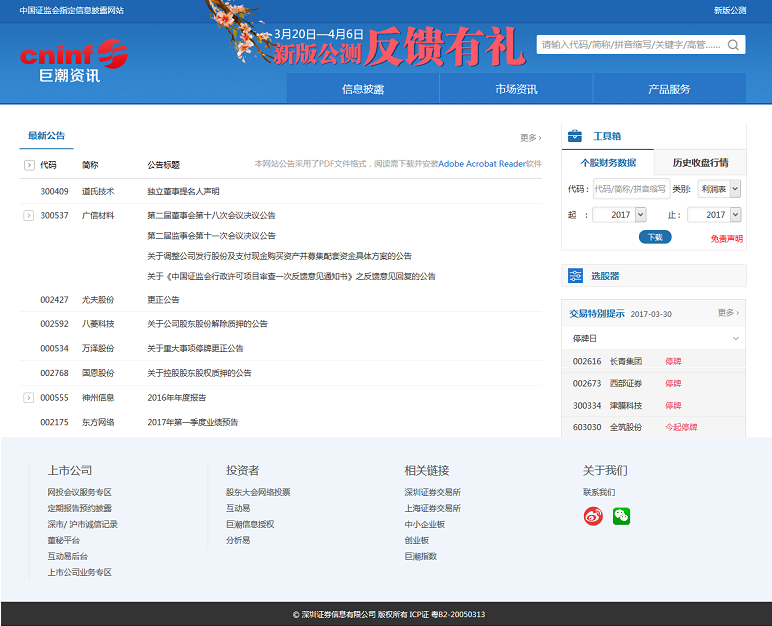
根据股票代码获取最新的公告信息,存档直接获取JSON数据解析。
成功实现并部署,每天爬取一次,运行良好。